Python结合Tesseract-OCR识别图像文字
环境配置
第一、下载安装 Tesseract-OCR。安装完成之后需要配置环境变量。配置完成后 tesseract -v查看版本信息,可以验证是否配置成功。
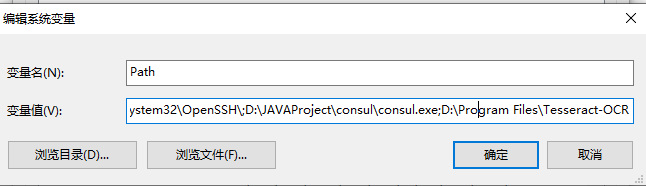
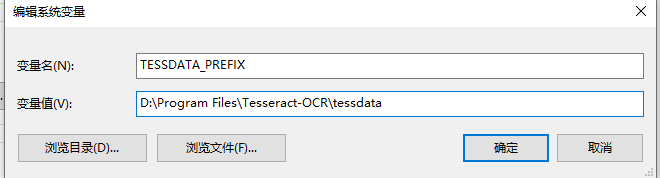
第二、安装语言包。tesseract默认是不识别中文的,需要下载中文语言包并配置环境变量。下载链接https://github.com/tesseract-ocr/tessdata
Python调用tesseract
需要安装包
pip install pillow
pip install pytesseract
import pytesseract
from PIL import Image
def handle_image():
try:
image = Image.open("33.png")
text = pytesseract.image_to_string(image,lang='chi_sim')
with open("output.txt",'w') as file:
print(text)
file.write(str(text))
except Exception as e:
print(e)
if __name__ == '__main__':
handle_image()
如何提高识别正确率???
标题:Python结合Tesseract-OCR识别图像文字
作者:zytops
地址:https://zytops.com/articles/2020/04/01/1585724664570.html